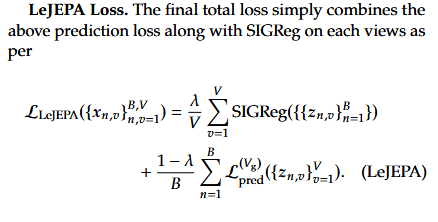I’ll use this blog post to go through the LeJEPA paper.
This paper introduces a new innovation to JEPA architectures, improving training by ensuring better embedding distributions.
JEPA architectures have long been championed by Yann LeCun as a potential path to “world models” / AGI. The basic idea is that you have a source and target encoder for differing views of inputs, where these views are typically altered versions of the same content. Learning shared representations potentially provides a path to shared understanding, which has potential benefits over the more standard tokenisation approach taken by LLMs. However, this is still a relatively niche area of Machine Learning, and hasn’t been widely used in research or industry. This paper attempts to provide innovations to JEPA architectures, and provides large scale evaluations of JEPA across a range of objectives.
Prompt 1 - Views
I’m struggling to understand what a “view” would be in practice. Can you give me a practical example “view” would typically look like, with examples in python code
🤖Reply🤖
🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠
In JEPA and similar self-supervised learning architectures, a view is simply an augmented or transformed version of the same input. The core idea is that different views of the same content should map to similar representations.
For images, views are typically created through augmentations:
from torchvision import transforms# Two different "views" of the same imageview1_transform = transforms.Compose([ transforms.RandomResizedCrop(224, scale=(0.4, 1.0)), transforms.RandomHorizontalFlip(), transforms.ColorJitter(0.4, 0.4, 0.4, 0.1), transforms.GaussianBlur(kernel_size=23, sigma=(0.1, 2.0)),])view2_transform = transforms.Compose([ transforms.RandomResizedCrop(224, scale=(0.4, 1.0)), transforms.RandomHorizontalFlip(), transforms.ColorJitter(0.4, 0.4, 0.4, 0.1),])# Same image, two different viewsimage = load_image("cat.jpg")view_1 = view1_transform(image) # e.g. cropped top-left, flipped, blurredview_2 = view2_transform(image) # e.g. cropped bottom-right, color shifted
For I-JEPA specifically, the views are more structured — they use masking:
# I-JEPA style: one view is the full image, # the other is the same image with patches masked outdef create_ijepa_views(image_patches):# Context view: keep some patches visible context_mask = random_block_mask(ratio=0.15) # ~15% visible context_view = image_patches * context_mask# Target view: the patches we want to predict target_mask = random_block_mask(ratio=0.30) # predict ~30% target_view = image_patches * target_maskreturn context_view, target_view
The model learns by trying to predict the target view’s representation from the context view’s representation — all in latent space (not pixel space), which is the key JEPA innovation.
Okay, that makes sense. Lets move on.
Prompt 2 - Probing Terminology
I’m struggling to understand the explanation around “probing” in Section 3 - “Latent Euclidean: Embeddings Should be Isotropic Guassian”. My understanding is that this is essentially describing training a downstream model on the raw embeddings, without any further training of the underlying model.
Can you confirm if my understanding is correct, and also explain the distinction between “Linear Probing” and “Nonlinear Probing”, with examples in python code.
🤖Reply🤖
🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠
Your understanding is correct! Probing is an evaluation technique where you freeze the pretrained encoder and train a small classifier on top of the frozen embeddings. This tests how useful the learned representations are “as-is” without any fine-tuning of the encoder.
Linear Probing — train only a single linear layer (essentially logistic regression) on the frozen embeddings:
import torch.nn as nnclass LinearProbe(nn.Module):def__init__(self, embed_dim, num_classes):super().__init__()self.classifier = nn.Linear(embed_dim, num_classes)def forward(self, x):returnself.classifier(x)# Usageencoder.eval() # freeze encoderfor param in encoder.parameters(): param.requires_grad =Falseprobe = LinearProbe(embed_dim=768, num_classes=1000)# Only probe.classifier parameters are trained
Nonlinear Probing — train a small MLP (multiple layers with nonlinearities) on the frozen embeddings:
Why the distinction matters: Linear probing is stricter — it can only succeed if the representations are already linearly separable. If a model does well on linear probing, it suggests the encoder has learned to organize features in a clean, disentangled way. Nonlinear probing is more forgiving and can untangle more complex feature arrangements, so the gap between them tells you something about representation quality.
Are you sure by “Nonlinear Probing” they mean an MLP. In the paper it says “We first define our prediction function. The training data consists of the N embeddings along with their training labels {(zn , yn)}N n=1. The prediction, using radius-based k-NN”…
🤖Reply🤖
🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠
You’re right, I apologize for the error! In this paper, they use k-NN (k-Nearest Neighbors) for nonlinear probing, not an MLP.
Linear Probing — still a linear classifier on frozen embeddings (as I described)
Nonlinear Probing (in this paper) — radius-based k-NN:
from sklearn.neighbors import KNeighborsClassifierimport numpy as np# Extract embeddings from frozen encoderembeddings = []labels = []for x, y in train_loader:with torch.no_grad(): z = encoder(x) embeddings.append(z.cpu().numpy()) labels.append(y.cpu().numpy())embeddings = np.concatenate(embeddings)labels = np.concatenate(labels)# k-NN probe (no training, just stores the embeddings)knn_probe = KNeighborsClassifier(n_neighbors=20, metric='euclidean')knn_probe.fit(embeddings, labels)# At inference: classify by majority vote of k nearest neighborstest_embedding = encoder(test_image).cpu().numpy()prediction = knn_probe.predict(test_embedding)
Why k-NN matters for this paper: k-NN classification directly depends on the geometry of the embedding space — it relies on Euclidean distances between points. This connects to the paper’s core argument about isotropic Gaussian embeddings: if your embeddings are well-distributed (isotropic), k-NN will work well because distances are meaningful. If embeddings collapse or cluster pathologically, k-NN fails. So k-NN probing is a natural way to evaluate whether the embedding space has the geometric properties they’re advocating for.
Prompt 3 - Isotropic Guassian
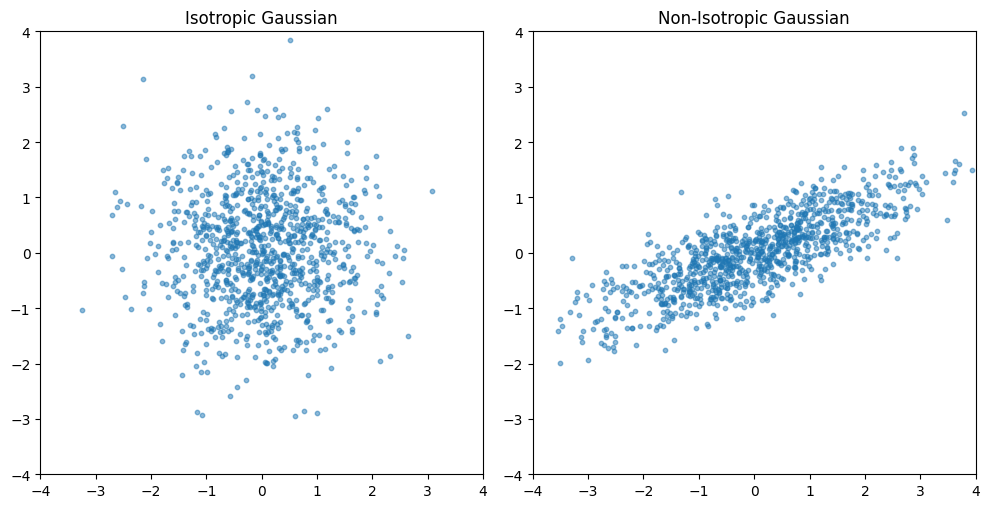
The paper describes how embeddings should be “Isotropic Guassian”. I understand that Guassian is a normal distrubtion, but I’m not sure what “Isotropic” means in this context. Can you explain what this means, and provide an example in python code.
🤖Reply🤖
🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠
Isotropic means “the same in all directions.” An isotropic Gaussian is a normal distribution where:
All dimensions have equal variance
Dimensions are uncorrelated (independent)
This means the covariance matrix is a scalar multiple of the identity matrix: Σ = σ²I
Visually, in 2D an isotropic Gaussian looks like a perfect circle, while a non-isotropic one looks like a stretched/rotated ellipse.
Why this matters for embeddings: If embeddings are isotropic Gaussian, then Euclidean distance is meaningful in all directions equally. If embeddings collapse into an elongated ellipse or cluster along certain axes, then distances become unreliable — two points might be “far” along a stretched axis but that distance isn’t semantically meaningful. The k-NN probing they use directly depends on these distances being well-behaved.
Okay I understand now. This to me takes a similar kind of approach to PCA to decorrelate features / embeddings.
Prompt 4 - SIGReg
I’ve just gone through the section “4 SIGReg: Reliable Isotropic Gaussian Regularization in High-Dimension”.
My basic understanding here is that statistical tests are used to ensure that the embeddings are isotropic guassian. Different statistical tests are considered, with Epps-Pulley used as it works well with current training hardware.
Your understanding is broadly correct, but with an important nuance: they’re not just testing whether embeddings are isotropic Gaussian — they’re using the statistical test as a regularization loss term during training.
The idea is: 1. Take a batch of embeddings 2. Compare them to samples from a reference isotropic Gaussian using a statistical test 3. Use the test statistic as a loss term to push the embeddings toward being isotropic Gaussian
The Epps-Pulley test is chosen because: - It’s a two-sample test (compares embedding batch vs. Gaussian samples) - It’s differentiable, so you can backpropagate through it - It’s computationally efficient and works well with GPU batch operations - It scales reasonably to high dimensions
The regularization actively shapes the embedding space geometry during training, rather than just measuring it afterward.
Oh right - I hadn’t understood that the guassian loss was additive to the predictive loss function, but that makes a lot more sense.
In this context, where would the guassian samples come from?
🤖Reply🤖
🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠
You simply generate them on-the-fly from a standard isotropic Gaussian — no learned or stored samples needed:
import torchdef sigreg_loss(embeddings): batch_size, embed_dim = embeddings.shape# Generate reference samples from standard isotropic Gaussian# Mean = 0, Covariance = Identity matrix gaussian_samples = torch.randn(batch_size, embed_dim, device=embeddings.device)# Compute Epps-Pulley statistic between embeddings and gaussian_samples loss = epps_pulley_statistic(embeddings, gaussian_samples)return loss
The key insight is that torch.randn() already gives you samples from an isotropic Gaussian (each dimension is independent with mean 0 and variance 1). So you’re essentially asking: “how different is my batch of embeddings from what I’d expect if they came from N(0, I)?”
The embeddings themselves may need to be normalized (mean-centered and scaled) before comparison, which the paper addresses — but the reference distribution is just the standard normal, trivially sampled.
I understand the basics, but now lets go into more detail in how SIGReg is actually applied.
The Epps-Pulley test is explained in the paper as
“The third family of tests is concerned with Empirical Characteristic Functions (ECF) which are the Fourier transform of the density function. The Epps-Pulley test [Epps and Pulley, 1983] is one of the most popular test and simply compares in weighted l2-norm the ECF of the data against a target CF.”
Can you first break down each element of this and explain. Specifically detail: - What is meant by ECF (Empirical Characteristic Functions), and how they differ from CF. - What is meant by “Fourier transform of the density function”.
Reference section 4, “SIGReg: Reliable Isotropic Gaussian Regularization in High-Dimension”, in the paper
🤖Reply🤖
🧠🧠🧠🧠🧠🧠🧠🧠
Characteristic Function (CF)
A characteristic function is a mathematical representation of a probability distribution. For a known distribution (like a Gaussian), you can derive its CF analytically from the formula. It completely describes the distribution — if two distributions have the same CF, they’re identical.
For a standard isotropic Gaussian, the CF has a known closed-form:
# CF of standard Gaussian at point t# φ(t) = exp(-||t||² / 2)def gaussian_cf(t):return torch.exp(-0.5* (t **2).sum(dim=-1))
Empirical Characteristic Function (ECF)
When you have actual data (like your embeddings), you don’t know the true underlying distribution — you only have samples. The ECF estimates the characteristic function from these samples:
The characteristic function is the Fourier transform of the probability density. This is just a mathematical equivalence:
Density function p(x): tells you the probability of seeing value x
Characteristic function φ(t): encodes the same information in “frequency space”
The Fourier transform converts between these representations. It’s useful because comparing distributions in frequency space can be easier and more numerically stable.
How Epps-Pulley uses this
The test compares: 1. The ECF of your embeddings (estimated from data) 2. The CF of the target isotropic Gaussian (known analytically)
It measures the weighted L2 distance between them:
def epps_pulley_intuition(embeddings):# Sample evaluation points t t_points = sample_evaluation_points()# ECF from our data ecf_embeddings = empirical_cf(embeddings, t_points)# CF of target Gaussian (closed form) cf_gaussian = gaussian_cf(t_points)# Weighted L2 distance difference = ecf_embeddings - cf_gaussian loss = (weights * torch.abs(difference) **2).sum()return loss
If your embeddings are truly isotropic Gaussian, their ECF should closely match the Gaussian CF, giving a low loss. The further they deviate, the higher the loss — which then pushes training to correct this.
Okay, so ECF just means the distribution function of our embeddings, and CF is the distribution function of the sampled guassian. l2 distance is the sum of squares of the differences between the 2 functions.
Weighting is used here - where do the weights come from?
At low frequencies (small t), the characteristic function captures broad distributional properties (mean, variance) — these are most informative
At high frequencies (large t), the CF oscillates rapidly and becomes noisy/less stable to estimate from finite samples
The weighting focuses the comparison on the frequency ranges that matter most for detecting departures from Gaussianity, while reducing sensitivity to noise in regions where the ECF estimate is unreliable.
In the original Epps-Pulley formulation, the weight function is chosen so the resulting integral has a closed-form solution, making it computationally tractable. The paper may specify their exact choice — but the principle is always: emphasize informative frequencies, downweight noisy ones.
Can you validate this against section 4.2 of the LeJEPA paper?
🤖Reply🤖
🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠
read_url(url=https://arxiv.org/html/2511.08544v1)
{"id":"toolu_011k5vpBKsMGV9Y1QkwSZ8oY","call":{"function":"read_url","arguments":{"url":"https://arxiv.org/html/2511.08544v1"}},"result":"'1. [1 Introduction](https://arxiv.org/html/2511.08544v1#S1)\\n 2. [2 Background and Notations](https://arxiv.org/html/2511.08544v1#S2)\\n 1. [2.1 Notations and Definitions](https://arxiv.org/html/2511.08544v1#S2.SS1 \"In 2 Background and Notations\")\\n 2. [2.2 The Need for Reliable Pretraining](https://arxiv.org/html/2511.08544v1#S2.SS2 \"In 2 Background and Notations\")\\n 3. [2.3 The Need for Actionable Theory](https://arxiv.org/html/2511.08544v1#S2.SS3 \"In 2 Background and Notations\")\\n 3. [3 Latent Euclidean: Embeddings Should be Isotropic Gaussian](https://arxiv.org/html/2511.0854<TRUNCATED>"}
I was able to read section 4.2. Looking at section 4.2.3 specifically, my explanation was largely correct but let me clarify the weighting:
From the paper:
The Epps-Pulley test compares the ECF against the target CF using a weighted L2 norm. The paper states: “The weight function is typically Gaussian, such as w(t) = e^{-t²/σ²} with σ commonly set to 1.”
So the weights are: - A Gaussian weighting function centered at zero - The parameter σ is typically set to 1 (though the paper notes this is adjustable) - This is a standard choice from the original Epps-Pulley test
The weighting is not learned or data-dependent — it’s a fixed design choice that emphasizes low frequencies where the characteristic function is most informative, as I described. The paper’s implementation in Algorithm 1 shows this directly with exp_f = torch.exp(-0.5 * t**2) serving as both the target Gaussian CF and the weighting function.
Can you explain the slicing logic? Specifically how it is applied in the SIGReg function? Please reference the paper to get their SEGReg implementation, making sure you copy the function exactly correctly as you’ve got this wrong in the past.
{"id":"toolu_018X6gQarVDBWHFsZ39A64dC","call":{"function":"read_url","arguments":{"url":"https://arxiv.org/html/2511.08544v1#S4"}},"result":"'## 4 SIGReg: Reliable Isotropic Gaussian Regularization in High-Dimension\\n\\nHaving established the isotropic Gaussian as the optimal embedding distribution ([Section\u02dc3](https://arxiv.org/html/2511.08544v1#S3 \"3 Latent Euclidean: Embeddings Should be Isotropic Gaussian\")), we now introduce Sketched Isotropic Gaussian Regularization (SIGReg)\u2013a distribution matching objective that is simultaneously (i) differentiable, (ii) scalable, (iii) provable, and (iv) interpretable. SIGReg builds on three key innovations. First, we formulate distribution matching as a statistical test under the null hypot<TRUNCATED>"}
I found the exact SIGReg implementation from Algorithm 1 in section 4.2.3. Here it is verbatim:
def SIGReg(x, global_step, num_slices=256):# slice sampling – synced across devices – dev =dict(device=x.device) g = torch.Generator(**dev) g.manual_seed(global_step) proj_shape = (x.size(1), num_slices) A = torch.randn(proj_shape, generator=g, **dev) A /= A.norm(p=2, dim=0)# – Epps-Pulley stat. see Sec. 4.3 for alt. –# integration points t = torch.linspace(-5, 5, 17, **dev)# theoretical CF for N(0, 1) and Gauss. window exp_f = torch.exp(-0.5* t**2)# empirical CF – gathered across devices – x = x @ A x_t = x.unsqueeze(2) * t # (N, M, T) ecf = (1j* x_t).exp().mean(0) ecf = all_reduce(ecf, op="AVG")# weighted L2 distance err = (ecf - exp_f).abs().square().mul(exp_f) N = x.size(0) * world_size T = torch.trapz(err, t, dim=1) * Nreturn T
The slicing logic explained:
Generate random projection directions (A): Sample num_slices random unit vectors in the embedding space. These are the “slices” or directions.
Why slice? Testing high-dimensional distributions directly is intractable. The Cramér-Wold theorem (Lemma 3 in the paper) says: if two distributions match on all 1D projections, they’re identical. So instead of testing in K dimensions, they test M random 1D projections and average the results.
Why it works with few slices: Section 4.3 shows that due to the smoothness of neural network outputs, you don’t need exponentially many directions — just O(K) suffices. Plus, resampling directions each training step means you cover the space over time.
The key insight: rather than one impossible high-dimensional test, do many cheap 1D tests along random directions and average them.
Prompt 5 - LeJEPA
The paper provides an implementation of LeJEPA (below).
def LeJEPA(global_views, all_views, lambd): ““” global_views and all_views are lists of tensors. lambd is a scalar. ““”
# Embedding of global views
g_emb = forward(torch.cat(global_views))
# Embedding of local views
# if resnet: skip with a_emb = g_emb
a_emb = forward(torch.cat(all_views))
# LeJEPA loss
centers = g_emb.view(-1, bs, K).mean(0)
a_emb = a_emb.view(-1, bs, K)
sim = (centers - a_emb).square().mean()
sigreg = mean(
SIGReg(emb, global_step)
for emb in a_emb
)
return (1 - lambd) * sim + lambd * sigreg
I think I’ve understood the SIGReg element of this, both I don’t understand how or why LeJEPA loss is also combining a sum of squares of the embeddings to the regularisation loss. Can you explain the purpose of this? Please also specifically explain the terminology “global views”, “local views” and “prediction loss” in this context.
Read section 5, “LeJEPA: Stable and Scalable Implementation”, before responding
{"id":"toolu_013Hp3ZeF8mS1N84nko8njB2","call":{"function":"read_url","arguments":{"url":"https://arxiv.org/html/2511.08544v1#S5"}},"result":"'## 5 LeJEPA: Stable and Scalable Implementation\\n\\nHaving established that isotropic Gaussians are the optimal embedding distribution for foundation models ([Section\u02dc3](https://arxiv.org/html/2511.08544v1#S3 \"3 Latent Euclidean: Embeddings Should be Isotropic Gaussian\")) and introduced SIGReg to achieve this distribution ([Section\u02dc4.2](https://arxiv.org/html/2511.08544v1#S4.SS2 \"4.2 SIGReg: Sketching the Epps-Pulley Test is Stable and Scalable \u2023 4 SIGReg: Reliable Isotropic Gaussian Regularization in High-Dimension\")), we now present the complete LeJEPA framework. We first evaluate candidate <TRUNCATED>"}
Now I can give you a clear explanation:
Global Views vs Local Views
This terminology comes from DINO/SwAV. For a single input image: - Global views: Larger crops (e.g., 224×224) that see most of the image — capture the “big picture” - Local views: Smaller crops (e.g., 96×96) that see only a portion — capture local details
All views are augmented versions of the same underlying image.
The Prediction Loss (sim)
The prediction loss enforces that all views of the same image should have similar embeddings. Specifically:
Compute the centroid (mean) of the global view embeddings for each sample: centers = g_emb.view(-1, bs, K).mean(0)
Each view’s embedding should be close to this centroid: sim = (centers - a_emb).square().mean()
This is the L2 distance between each view embedding and the average of the global views. It’s the invariance objective — different augmented views of the same image should map to the same representation.
Why Both Losses?
Prediction loss alone → embeddings could collapse (everything maps to the same point — trivially “similar”)
SIGReg alone → embeddings would be isotropic Gaussian but wouldn’t capture any semantic meaning
Combined → embeddings are forced to be similar across views (semantic consistency) while also being spread out in an isotropic Gaussian (prevents collapse, enables good k-NN)
The lambd parameter balances these two objectives.
Okay - so in this context, the prediction loss they use here is equivalent to e.g. cross entropy loss for a classification model?
Yes, that’s a good analogy in terms of their role in the loss function — both are the primary task objective:
Classification
LeJEPA
Cross-entropy loss (match predictions to labels)
Prediction loss (match view embeddings to centroid)
Weight decay / dropout (regularization)
SIGReg (regularization)
The key difference is: - Cross-entropy is supervised — you have external ground truth labels - LeJEPA prediction loss is self-supervised — the “target” is internally generated (the centroid of global views)
But functionally they serve the same purpose: the prediction loss drives the model to learn meaningful representations, while the regularization (SIGReg) prevents degenerate solutions (collapse in LeJEPA’s case, overfitting in classification).
Prompt 6 - DINO explanation
The paper references “DINO [Caron et al., 2021]” in relation to how views are generated. I’m not familiar with this work, can you explain?
🤖Reply🤖
🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠
DINO (Self-Distillation with No Labels) is a self-supervised learning method from Meta AI that trains vision transformers without any labeled data.
The core idea: - You have two networks: a student and a teacher (both same architecture) - Given an image, create multiple augmented views (crops of different sizes) - Student sees small crops, teacher sees larger “global” crops - Train the student to match the teacher’s output distributions - The teacher is updated as an exponential moving average (EMA) of the student weights — not through gradient descent
# Conceptual DINO training stepglobal_crops = [large_crop_1, large_crop_2] # e.g. 224x224, covering 50-100% of imagelocal_crops = [small_crop_1, ..., small_crop_6] # e.g. 96x96, covering 5-50% of image# Teacher only sees global viewsteacher_outputs = [teacher(crop) for crop in global_crops]# Student sees all viewsstudent_outputs = [student(crop) for crop in global_crops + local_crops]# Loss: student should match teacher's output distributionloss = cross_entropy(student_outputs, teacher_outputs)# Teacher update: EMA of student (no gradients)teacher.params =0.99* teacher.params +0.01* student.params
Why it’s relevant to LeJEPA: DINO established the multi-crop view generation strategy and the student-teacher EMA framework that many JEPA methods build upon. The “views” in LeJEPA follow a similar philosophy — different augmented perspectives of the same input that should map to consistent representations.
Prompt 7 - Hyperparameter Tuning
In section “6 LeJEPA: Empirical Validation” it discusses tuning parameter λ. What is this parameter?
🤖Reply🤖
🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠
This is the weighting coefficient for the SIGReg regularization loss that we discussed earlier. It controls how much the Gaussian regularization contributes relative to the main JEPA prediction loss:
total_loss = prediction_loss + λ * sigreg_loss
λ = 0: No regularization, embeddings can collapse or become non-isotropic
λ too small: Regularization has little effect, embedding geometry may be poor
λ too large: Over-regularizes, may harm the predictive objective
λ just right: Embeddings stay isotropic Gaussian while still learning useful representations
The paper empirically tunes this to find the sweet spot where the regularization improves downstream task performance (linear/k-NN probing) without interfering too much with the core representation learning objective.
Yeah - makes total sense. For ref the paper recommends the following conditions for training:
λ = 0.05
Vg = 2
Vl = 8
batch size ≥ 128
Where Vg is the number of global views, and Vl is the number of local views.
Prompt 7 - Stop Gradients
The paper refers to stop-gradients used in other JEPA architectures. Explain what this means?
🤖Reply🤖
🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠🧠
Stop-gradient is a technique where you prevent gradients from flowing back through part of the network during backpropagation. In JEPA/DINO-style architectures, it’s crucial for preventing collapse.
The problem it solves: In a student-teacher setup where both networks see views of the same input, there’s a trivial solution — both could output the same constant vector for everything. The loss would be zero, but the representations would be useless.
How it works:
import torch# Without stop-gradient: both branches receive gradientsloss = mse_loss(student_output, teacher_output)loss.backward() # Gradients flow to BOTH student AND teacher# With stop-gradient: only student receives gradientsloss = mse_loss(student_output, teacher_output.detach())loss.backward() # Gradients flow ONLY to student
The .detach() call (or stop_gradient in other frameworks) tells PyTorch to treat that tensor as a constant during backprop.
In JEPA architectures: - The target encoder (teacher) has stop-gradient applied - The context encoder (student) receives all the gradients - The teacher is updated separately via EMA (exponential moving average) of the student
# Typical JEPA/DINO update patternprediction = predictor(context_encoder(context_view))target = target_encoder(target_view).detach() # stop-gradient hereloss = mse_loss(prediction, target)loss.backward() # Only updates context_encoder and predictor# Teacher updated via EMA, not gradientstarget_encoder.params =0.99* target_encoder.params +0.01* context_encoder.params
This asymmetry prevents collapse because the teacher provides a slowly-moving target that the student chases, rather than both networks converging to the same trivial solution.
Have I understood correctly that this is not required in LeJEPA? If so, why not?
Yes, you’ve understood correctly! LeJEPA removes the need for stop-gradients (and the EMA teacher update).
Why stop-gradients exist in standard JEPA: They’re a heuristic to prevent representation collapse — without them, both encoders can converge to outputting constant vectors.
Why LeJEPA doesn’t need them: The SIGReg regularization explicitly prevents collapse by forcing embeddings to be isotropic Gaussian. If embeddings tried to collapse to a single point, they would massively violate the Gaussian constraint — the regularization loss would spike.
This is one of the paper’s key contributions — replacing the “heuristic” of stop-gradients with a principled, mathematically grounded regularization. The title hints at this: “Provable and Scalable Self-Supervised Learning Without the Heuristics.”
The benefit is both theoretical (you can prove things about the embedding space) and practical (simpler training dynamics, no need to tune EMA momentum schedules).
6 LeJEPA: Empirical Validation
I don’t really have any questions on this section.
In summary:
This technique can be applied to a range of architectures, where other techniques are specific to architectures like ViT
The performance of the underlying JEPA model has a high correlation with performance of downstream tasks, which has been an issue with previous JEPA implementations.
Overall, this technique outperforms current SOTA (DINO and IJEPA).
Closing Thoughts
This was an interesting read, and I now have a much better understanding of JEPA architectures and the specific innovation introduced by this paper.
At some point I’d like to implement a JEPA architecture and run some training experiments. Since this paper focuses strictly on vision tasks, it could be interesting to explore whether the same technique applies to language - a potential follow-up blog.
As for using LLMs to assist with paper comprehension, I found it very helpful. I often struggle with terminology in mathematical papers, and being able to pause and ask for explanations with code examples made the concepts much easier to grasp.
That said, I suspect this blog may be hard for others to follow. In future read-throughs, I’ll think about how to make these more accessible to readers.